.svg)
Tutorials
Feb 12, 2024
Continuously ingest documents into a vector store using Quix, Qdrant, and Apache Kafka
Learn how to set up a decoupled, event-driven pipeline to embed and ingest new content into a vector store as soon as it's published.

Vector Databases and The Rise of Semantic Search
Although many of us feel like Google’s search results are getting worse, the technology behind the matching has gotten better and better. Google has invested heavily in semantic search which allows them to provide semantically similar search results that don't necessarily contain any of the keywords that you type, but still have a similar meaning. For example, “monkey parks in Malaysia'' might match “Sepilok Orangutan Sanctuary in Borneo”.
And the technology behind this improvement? — the vector database. That much-hyped technology is indeed helping to improve search. Google also uses its own vector storage and retrieval solution (Vertex AI Vector Search) but there are plenty of other startups such as Pinecone, Weviate, and Qdrant that produce similar technology albeit not at the same level of performance as Vertex. Vector databases aren’t just for general search, though. They’re also handy for searching news headlines and product catalogs. You can potentially increase sales if you’re able to match product searches more accurately, and you have to worry less about including precise keywords in product descriptions.
The challenge of recency
One significant challenge is keeping the vector databases up to date. On the surface, this problem feels very similar to the indexing problem in traditional keyword-powered search. You need to figure out how to index new content as it arrives. However, getting new content into a vector database is more challenging because it's more computationally expensive. You need a specialized ML model called an “embedding model” to turn new text into vectors (aka embeddings) before it can be inserted into a vector database, and the user’s query must also be “embedded” using the same model, otherwise the results won’t match.
Using continuous, event-based vector ingestion
There are various solutions to this challenge, but one is to use an event-based system such as Apache Kafka. Here’s the basic idea: as soon as new content is entered into a system (or crawled in the case of search engines), an event is emitted to Kafka with the text of the content as a payload. A consumer process listens for new content and passes it to the embedding model as it arrives. The resulting vectors are passed to a downstream Kafka topic where any vector database can consume and ingest the vectors at its own pace.
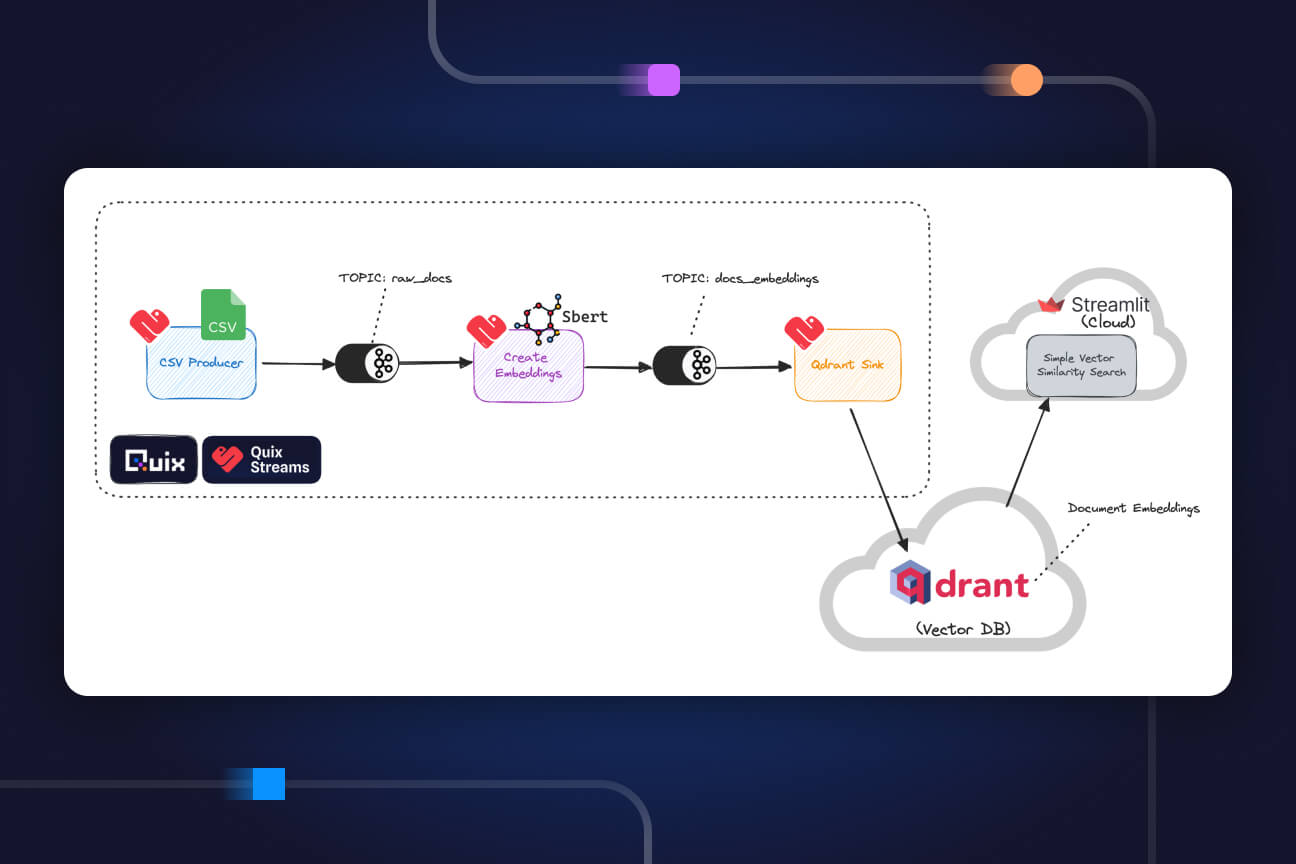
To show you how this works, we’ve created a proof-of-concept using Quix Streams, for interacting with Kafka and Qdrant as the vector store. The following diagram illustrates the basic architecture:

You can try out a minimal, standalone version of this pipeline in Google Colab with the following notebook or follow the tutorial steps in the Quix documentation.

You can also see it working as an end-to-end serverless pipeline by cloning the Vector Ingestion template in the Quix Cloud. In this version, we’ve included a Streamlit dashboard so it’s easier to try out the semantic search.
How to test the semantic matching in Quix Cloud
To try out the pipeline, first clone the vector ingestion template (for more information on how to clone a project template, see the article How to create a project from a template in Quix). We’ll use a similar path to the one outlined in the notebook.
Before you clone the pipeline, you’ll also need to sign up for a free trial account with Qdrant Cloud (you can sign up with your GitHub or Google account). When you clone the project template in Quix, you’ll be asked for your Qdrant Cloud credentials.
What's Qdrant?
Qdrant is a vector database that is optimized for storing and querying high-dimensional vectors efficiently. Qdrant is popular because it can handle complex queries with filtering and ranking, which are crucial for building recommendation systems, search engines, and similar AI-driven applications. It's built in Rust which offers a winning combination of speed and thread safety. And it's got a great Python client which is why we used it for this template.

Run the first ingestion test
- Press play on the first job (with the name that starts with “PT1…”)—hover your mouse over the “stopped” button to press play.
This will ingest the first part of the same “sci-fi books” sample dataset that we used in the notebook. - On the “Streamlit Dashboard service”, click the blue “launch” icon to open the search UI.
- Search for “book like star wars” — the top result should be “Dune”

We can guess it matched because the words in the description are semantically similar to the query: “planet" is semantically close to "star" and "struggles" is semantically close to "wars".
Run the second ingestion test
- Press play on the second job (with the name that starts with “PT2…”)
This will ingest the second part of the dataset with more relevant matches
- In the Streamlit-based search UI, search for “books like star wars” again—the top result should now be “Old man’s war”, and the second result should be “Dune”.

We can assume that Dune has been knocked off the top spot because the new addition has a more semantically relevant description: the "term" war is almost a direct hit, and "interstellar" is probably semantically closer to the search term "star" than "planet".
Lessons learned
As I’ve stated in the accompanying notebook, the point of this exercise was not to delve into the matching logic behind semantic search, rather how we can use Apache Kafka to keep data up-to-date.
Indeed, keeping the underlying data fresh is a crucial component to search quality. We saw how we were able to give the user more semantically accurate search results by updating the vector store.
We could have just updated the vector store manually, by embedding the contents of the CSV and writing to the vector store in batches. Yet this introduces several questions such as:
- How does this work in a production ecommerce scenario where your product catalog is constantly changing?
- How do you organize your batches and what is an acceptable delay between the product arriving in the catalog and it matching user search queries?
If you set up an event-based system where embeddings are created and ingested as soon as data is entered (for example via CDC), you don't have to deal with these questions, which is why Apache Kafka is so popular.
Many large enterprises are already using event based solutions such as Apache Kafka for traditional search indexing. For example, the DoorDash engineering team produced the article “Building Faster Indexing with Apache Kafka and Elasticsearch” which provides a spot-on description of the problem-solution fit. The challenges involved in keeping text embeddings up to date are similar so it makes sense to apply the same approach to text embeddings.
Extending the project
There are many ways you can turn this template into a production use case. Here are a few suggestions:
Integrating Semantic Search into a RAG workflow
We can’t discuss vector databases without mentioning RAG (Retriel Augmented Generation). This is where you give the results of the semantic search to a large language model such as GPT4 to answer a question in a conversational manner. For example, suppose you have been ingesting business news headlines since the beginning of 2023 into your vector database. You might ask “what crypto companies went bankrupt in 2023?”. The semantic search might return a list of pretty good matches, but it’s even easier if GPT4 gives you a more succinct answer. In this case you would pass the search results to GPT4 (or GPT3.5) first and have it use this knowledge to give you an informed answer. Since GPT4’s knowledge cutoff is April 2023, it would not be able to answer this question accurately without the help of these more current search results. I'm also in the process of using this pipeline to create a RAG search function for the Quix documentation. The docs are regularly updated, so new content needs to be ingested as soon as it's published.
- For more guidelines on how to to use RAG to augment an LLM’s knowledge, check out Qdrant’s Basic RAG notebook.
Implementing CDC (Change Data Capture)
You probably won’t be ingesting a static JSON file in a production scenario so you’ll need a more robust ingestion solution. For example, if you’re looking to use semantic search for product catalogs, you might want to emit an event whenever a new entry is added to a database—through CDC. Quix has several CDC connectors that support this use case. For instance, if you use a postgres database, you can use the Quix Postgres CDC connector to ingest changes to your database.
We've also started work on a project template that shows you CDC in action.
Crawling the web or polling an API
Another use case is ingesting text content via an API (such as the Reddit API or News API) or using a scraping library such as Scrapy. Once you have this content in a vector database you can build up-to-date semantic search for a specific domain of expertise, or perform more advanced text analysis tasks such as dynamic topic modeling. You can reuse this same pipeline architecture from the project template in Quix Cloud but increase the replica count for better horizontal scalability.
- For more questions about how to set up this architecture with Quix and CDC, join our Quix Community Slack and start a conversation.
- To learn more about the Quix Streams Python library, check out the relevant section in the Quix documentation.
- To see more project template demos, check out our template gallery—for example, why not try our LLM-based “AI Customer Support” template?
Last updated:
Apr 11, 2024

Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.