.svg)
Ecosystem
May 16, 2024
Choosing a Python Kafka client: A comparative analysis
Assessing Python clients for Kafka: kafka-python, Confluent, and Quix Streams. Learn how they compare in terms of DevEx, broker compatibility, and performance.

Introduction
Apache Kafka is often used to power elaborate real-time use cases like fraud detection, recommendation systems, and real-time monitoring and predictive maintenance. These types of use cases require a stateful stream processing engine that works in tandem with Kafka, often leading to a complex architecture with many moving parts.
But Kafka is a versatile tool that can be used on its own in certain scenarios, without the need for a complementary stream processing technology. For example, due to its pub/sub messaging capabilities, Kafka is an excellent choice for integrating disparate systems. Similar to how the nervous system receives and sends signals throughout the body to coordinate actions, Kafka can efficiently ingest streams of data from many sources and redistribute them to various parts of the system (applications, services, databases, etc.) in real time.
After ingesting data from sources, you might do some sort of light, stateless processing before sending it to destination systems. This may entail common operations like filtering, mapping, scrubbing (cleansing), enriching, and type conversion. These stateless transformations are needed to ensure data is standardized, clean, well-structured, and suitable for consumption by downstream systems.
The great thing is that you can use an Apache Kafka client for such basic transformations on streaming data (rather than using Kafka and a dedicated processing solution). This simplifies your architecture and reduces system complexity.
But what Python Kafka clients can you use for this purpose and how do they compare? This is what I aim to answer in this article.
Why Python and Kafka are a good match
Python is arguably the most commonly used language in the world for data science, data engineering, data analysis, and machine learning.
Such use cases often require collecting (and processing) high volumes of streaming data, while Kafka is the industry standard for working with data streams in a scalable, fault-tolerant manner.
It’s no surprise, then, to see Kafka being used alongside Python in production environments. For instance, Robinhood depends on a microservice-based architecture that leverages Kafka and Python. Another example is Netflix. The streaming giant relies heavily on Python. Netflix is also one of the biggest Kafka users globally.
What Python Kafka clients are we comparing?
This article zooms in on three Python clients for Kafka: Confluent’s Kafka Python client, the kafka-python client library, and Quix Streams. The first two have historically been the most popular Python Kafka clients around. Meanwhile, Quix Streams is a more recent solution that aims to simplify working with Kafka and data streams using pure Python.
I’ll compare them based on criteria such as:
- Developer experience
- Licensing and broker compatibility
- Performance considerations
However, before we jump into the comparison, let’s give a quick overview of the three Kafka clients.
Confluent Kafka Python client
The Confluent Kafka Python package is a lightweight wrapper around the high-performance librdkafka library, which is a C/C++ implementation of the Apache Kafka protocol.
Key capabilities
- Provides high-level Producer, Consumer, and AdminClient classes to read and write messages, as well as manage Kafka topics.
- Supports advanced Confluent and Kafka features and integrations, such as Confluent Schema Registry.
- Can implement simple transformations like serialization format changes or message filtering as part of the consumption process.
kafka-python client library
kafka-python is an open-source library that offers a Pythonic API for working with Apache Kafka. Unlike the Confluent Python client, it doesn’t depend on any underlying external libraries and is entirely implemented in Python.
Key capabilities
- Specifically designed classes for producing messages to Kafka topics (KafkaProducer) and consuming messages from Kafka topics (KafkaConsumer). They are intended to operate as similarly as possible to Kafka’s Java client.
- Offers features like topic management and synchronous and asynchronous messaging.
- Can perform transformations on the fly during message consumption or production, like adding headers, modifying message values, or filtering based on specific criteria.
Quix Streams
Quix Streams is an open-source, cloud-native library for data streaming and stream processing using Kafka and pure Python. It’s designed to give you the power of a distributed system in a lightweight library by combining Kafka's low-level scalability and resiliency features with an easy-to-use Python interface.
Key capabilities
- Can be used as a Kafka client to produce and consume messages (it wraps Confluent’s Python Kafka library for this purpose).
- Supports both low-level, stateless transformations, and more complex, stateful operations. Offers a Streaming DataFrame API (similar to pandas DataFrame) for tabular data transformations.
- Easily integrates with the entire Python ecosystem (pandas, scikit-learn, TensorFlow, PyTorch, etc).
- Designed to run and scale resiliently via container orchestration (Kubernetes).
Comparing the developer experience of Python Kafka clients
We’ll kick off this analysis by comparing the DevEx provided by kafka-python, Quix Streams, and the Confluent Kafka Python package. First, we’ll look at some code examples to get a feel of what it’s like working with these Python Kafka clients. Then, we’ll review things like the learning curve, docs & learning resources, and maturity for each of them.
Code demonstration
I’ll go through a basic usage example, demonstrating how to use the three Python Kafka clients to:
- Read data from an existing Kafka topic.
- Perform a stateless transformation (convert miles per hour to kilometers per hour).
- Send the transformed output to another existing Kafka topic.
kafka-python client code example
import json
from kafka import KafkaConsumer, KafkaProducer
def mph_to_kmph(mph):
"""Convert miles per hour to kilometers per hour."""
return mph * 1.60934
# Consumer setup to consume JSON messages from source topic ('source_speed_mph')
consumer = KafkaConsumer(
'source_speed_mph',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
value_deserializer=lambda x: json.loads(x.decode('utf-8'))
)
# Producer setup to produce JSON messages to destination topic ('destination_speed_kmph')
# The messages are converted from miles/hour to kilometers/hour
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
# Process and produce messages asynchronously
try:
for message in consumer:
mph = message.value['speed'] # Extracts speed in mph from the consumed message
kmph = mph_to_kmph(mph) # Converts mph to km/h
processed_message = {'speed': kmph}
producer.send('destination_speed_kmph', processed_message) # Sends the converted speed to 'destination_speed_kmph' topic
producer.flush() # Ensures all messages are sent
It’s a straightforward implementation with a clear separation of concerns (separate consumer and producer setups). The code should theoretically be easy to understand for developers familiar with Python and Kafka.
Confluent Kafka Python code example
from confluent_kafka import Consumer, Producer, KafkaError
import json
def mph_to_kmph(mph):
"""Convert miles per hour to kilometers per hour."""
return mph * 1.60934
# Consumer setup to consume JSON messages from source topic ('source_speed_mph')
consumer_config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'group1',
'auto.offset.reset': 'earliest',
'enable.auto.commit': True,
'value.deserializer': lambda x: json.loads(x.decode('utf-8'))
}
consumer = Consumer(consumer_config)
consumer.subscribe(['≈'])
# Producer setup
producer_config = {
'bootstrap.servers': 'localhost:9092',
'value.serializer': lambda x: json.dumps(x).encode('utf-8')
}
producer = Producer(producer_config)
# Function to transform miles per hour to kilometers per hour
def process_message(msg):
mph = msg['speed']
kmph = mph_to_kmph(mph)
return {'speed': kmph}
try:
while True:
msg = consumer.poll(timeout=1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# End of partition event
continue
elif msg.error():
print('KafkaError: {}'.format(msg.error()))
else:
# Message is a Python dictionary
mph_value = process_message(msg.value())
producer.produce('destination_speed_kmph', mph_value) # Sends the converted speed to 'destination_speed_kmph' topic
producer.flush()
The code is slightly more verbose compared to the kafka-python snippet (and significantly more so compared to Quix Streams). This is due to additional configuration options and error handling. Bear in mind that the snippets here are simple, demonstrative examples. In real-life scenarios, the code you write when using Confluent’s Kafka Python client would likely be even more verbose.
Quix Streams code example
from quixstreams import Application
# The 'Application' class consumes messages from an input topic, processes them, and then produces the result to an output topic.
app = Application(broker_address="localhost:9092")
input_topic = app.topic("source_speed_mph")
output_topic = app.topic("destination_speed_kmph")
# Reads JSON messages from input topic and converts them to Streaming DataFrame (SDF) tabular format
sdf = app.dataframe(input_topic)
# Transforms miles per hour to kilometers per hour
sdf["speed_km_h"] = sdf["speed_mph"] * 1.60934
# Send rows from SDF back to the output topic as JSON messages
sdf = sdf.to_topic(output_topic)
Quix Streams offers a high-level abstraction over Kafka with pandas DataFrame-like operations (read this article to learn more about the Quix Streaming DataFrame API). This declarative syntax enhances readability and reduces code length, providing a streamlined experience to Python developers.
The snippet above shows how to use Quix Streams to consume data from a Kafka topic, transform it, and write the output to another Kafka topic. But you can also use Quix Streams to ingest data from a non-Kafka source (e.g., a CSV file or a fixed dictionary), transform it, and produce it to a Kafka topic. Here’s an example:
from quixstreams import Application
# import additional modules as needed
import random
import os
import json
# create an Application
app = Application(consumer_group="data_source", auto_create_topics=True)
# define the topic using the "output" environment variable
topic_name = os.environ["output"]
topic = app.topic(topic_name)
# this function loads the file and sends each row to the publisher
def get_data():
"""
A function to generate data from a hardcoded dataset in an endless manner.
It returns a list of tuples with a message_key and rows
"""
# define the hardcoded dataset, representing vehicle sensor readings
data = [
{"sensor": "speed", "vehicle_id": "vehicle1", "speed_kmh": "55.5", "time": "1577836800000000000"},
{"sensor": "speed", "vehicle_id": "vehicle2", "speed_kmh": "62.1", "time": "1577836801000000000"},
{"sensor": "speed", "vehicle_id": "vehicle1", "speed_kmh": "53.7", "time": "1577836803000000000"},
{"sensor": "speed", "vehicle_id": "vehicle2", "speed_kmh": "64.3", "time": "1577836804000000000"},
{"sensor": "speed", "vehicle_id": "vehicle1", "speed_kmh": "52.8", "time": "1577836806000000000"},
{"sensor": "speed", "vehicle_id": "vehicle2", "speed_kmh": "66.2", "time": "1577836808000000000"},
{"sensor": "speed", "vehicle_id": "vehicle1", "speed_kmh": "57.4", "time": "1577836810000000000"},
{"sensor": "speed", "vehicle_id": "vehicle2", "speed_kmh": "61.9", "time": "1577836812000000000"},
{"sensor": "speed", "vehicle_id": "vehicle1", "speed_kmh": "56.0", "time": "1577836814000000000"},
{"sensor": "speed", "vehicle_id": "vehicle2", "speed_kmh": "63.5", "time": "1577836816000000000"},
{"sensor": "speed", "vehicle_id": "vehicle1", "speed_kmh": "54.9", "time": "1577836818000000000"},
{"sensor": "speed", "vehicle_id": "vehicle2", "speed_kmh": "64.8", "time": "1577836820000000000"}
]
# create a list of tuples with row_data
data_with_id = [(row_data) for row_data in data]
return data_with_id
def main():
"""
Read data from the hardcoded dataset and publish it to Kafka
"""
# create a pre-configured Producer object.
with app.get_producer() as producer:
# iterate over the data from the hardcoded dataset
data_with_id = get_data()
for row_data in data_with_id:
json_data = json.dumps(row_data) # convert the row to JSON
# publish the data to the topic
producer.produce(
topic=topic.name,
key=row_data['vehicle_id'],
value=json_data,
)
print("All rows published")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("Exiting.")
Note the use of with app.get_producer()as producer. This is known as a context manager, a mechanism that automatically manages resources in a block of code. In our case, the context manager guarantees that the Kafka producer is properly created at the start of the with block and appropriately closed and cleaned up after the block is executed. This helps ensure efficient resource management, preventing resource leaks. It also makes your code more concise, readable, and easier to maintain. Note that context managers are exclusive to Quix Streams — they are not natively supported by kafka-python and Confluent’s Python client. In those clients, you need to explicitly close the connection with producer.close().
Learning curve, resources, and maturity
The learning curve, the quality and depth of documentation, and the maturity level — these are all important factors to consider when choosing a software solution. So how do the three Python Kafka clients compare based on these criteria?
Both Confluent and Quix Streams offer good (albeit not exhaustive) documentation. Beyond docs, Confluent offers minimal learning resources for its Python Kafka client (just a couple of blog posts and an end-to-end tutorial). Quix fares much better in this regard, with plenty of blog posts, tutorials, and pre-made projects to help get you started. Meanwhile, kafka-python offers a detailed API reference. The rest of the documentation consists of a handful of basic, brief pages. kafka-python doesn’t provide any additional learning resources (such as end-to-end tutorials or blog posts).
The Confluent Kafka Python client has the steepest learning curve. That’s because you not only have to learn how to use the client but also gain a good grasp of the broader Confluent ecosystem. However, provided you are already familiar with Confluent products and only have to learn how to use the Kafka Python client, the curve is much shorter (perhaps a few days). kafka-python and Quix Streams have a similar learning curve of a few days. The former offers straightforward APIs, but the lack of examples, tutorials, and how-to guides means you will spend a few days testing and understanding the client. Even though Quix is more complex than kafka-python, the fact that it offers more extensive documentation and additional learning resources means you’ll spend less time figuring things out yourself. Additionally, the Quix (Streams) community is very responsive, and you should be able to quickly get help if needed.
kafka-python is the oldest Python client for Kafka (it’s been around for a decade). It seems to have been regularly maintained up until 2020. However, there were zero new releases between September 2020 and March 2024. That’s a very long hiatus for a software product. Perhaps the maintainers had other priorities, and couldn’t afford to invest more time in its development. That’s always a risk with open-source projects with no commercial backing. In contrast, the Confluent Python Kafka client and Quix Streams benefit from significant commercial backing, and they’re actively maintained, with a regular cadence of new releases.
Comparing Python Kafka clients based on licensing and broker compatibility
So far, we’ve seen how Quix Streams, kafka-python, and Confluent’s Kafka Python client compare when it comes to developer experience. DevEx is certainly a critical aspect, but it isn’t the only one. You also need to consider things like broker compatibility and licensing. These are important criteria to have in mind from an operational perspective.
Here’s how the three Python Kafka clients compare:
And here are some key takeaways:
- All three Kafka Python clients come with a permissive, open-source license. This means you are free to use, modify, and distribute any of these three software solutions.
- kafka-python theoretically works with any Kafka broker (version 0.8 or later), be it managed by a vendor or self-hosted. In practice, though, you’d have to test to see how well the client works with hosted Kafka solutions. For instance, there wouldn’t be much point connecting kafka-python to a Confluent Cloud Kafka broker. That’s because the kafka-python client lacks advanced features provided by Confluent’s own Kafka clients, which are designed to fully leverage and integrate with the Confluent Cloud ecosystem.
- Confluent’s Python client is particularly well-suited for use with Confluent Platform and Confluent Cloud, enabling full utilization of Confluent capabilities and features like Schema Registry. Additionally, similar to kafka-python, Confluent’s Python client theoretically works with any Kafka broker (version 0.8 or later), be it self-hosted or managed by another vendor. In practice, though, I haven’t come across concrete examples of companies using Confluent's Python client alongside Kafka brokers managed by other vendors.
- While kafka-python and the Confluent Python client work with Kafka brokers version 0.8 or later, Quix Streams works with Kafka brokers version 0.10 or later. Quix Streams is guaranteed to work with self-hosted Kafka brokers and has been extensively tested to ensure seamless compatibility with various vendor-managed Kafka brokers. This is in contrast to the two other Python Kafka clients we’re discussing; in their case, some trial and error may be required to find out exactly how well they work with vendor-managed Kafka deployments.
Comparing the performance of Python Kafka clients
As previously mentioned, Confluent’s Python Kafka package wraps the librdkafka C/C++ library. Note that C/C++ is generally faster and more efficient in terms of memory usage than Python. This means that the Confluent Python client theoretically offers better performance compared to kafka-python (which is a pure Python implementation).
According to its GitHub page, librdkafka “was designed with message delivery reliability and high performance in mind, current figures exceed 1 million msgs/second for the producer and 3 million msgs/second for the consumer”. Those are impressive numbers, and Confluent Kafka Python inherits them. I couldn’t find any similar numbers for the kafka-python library.
Since Quix Streams wraps Confluent’s Python Kafka client, its performance characteristics as a Kafka producer and consumer are similar to those of the Confluent Python client. Built by Formula 1 engineers with extensive knowledge about data streaming and stream processing at scale, Quix Streams can reliably handle up to millions of messages/multiple GB of data per second, with consistently low latencies (in the millisecond range).
So, to sum it up, if you require the best possible performance under high load, you should opt for the Confluent Python client or Quix Streams. Meanwhile, kafka-python seems more suitable for small and medium workloads where a moderate performance level is acceptable. At least in theory. However, it’s often the case that software will perform better in some scenarios and worse in others. That’s why I strongly encourage you to test all three Python Kafka clients to see how they behave under the specific requirements of your use case.
Upgrading to stateful stream processing
Organizations usually start small with Kafka. For instance, in an e-commerce scenario, you might initially use Kafka to ingest orders and forward them to various services for consumption (e.g., inventory management system, order processing service). Kafka’s pub/sub capabilities, together with some basic stateless processing that can be handled by the Kafka client (e.g., enriching orders with additional information, or changing data formats) are all you need for this use case.
However, in time, requirements tend to change and evolve. At some point, you might also want to analyze user clickstream data in real time to serve personalized offers and item suggestions to people browsing the online shop. Or you might want to analyze payment transactions to identify the potentially fraudulent ones.
Kafka can certainly help with these use cases too. It’s ideal for ingesting clickstreams and streams of transaction data and routing them to the appropriate consuming services. However, things are more complicated on the data processing side. Fraud detection and clickstream analysis are complex use cases that require stateful operations like windowing and aggregations.
These kinds of stateful operations go beyond the capabilities of Confluent’s Python client and the kafka-python client library (which are only designed to produce/consume messages and implement basic, stateless transformations). If you’re using any of these two Python Kafka clients, you’d have to add a dedicated stream processing component to your architecture to handle stateful transformations. Presumably a Python stream processor.
PyFlink (Python interface for Apache Flink) and PySpark (Python interface for Apache Spark) are the most well-known Python stream processing engines. They are both very powerful distributed systems, with rich feature sets. The downside is that you’re adding a new component to your stack, increasing overall system complexity.
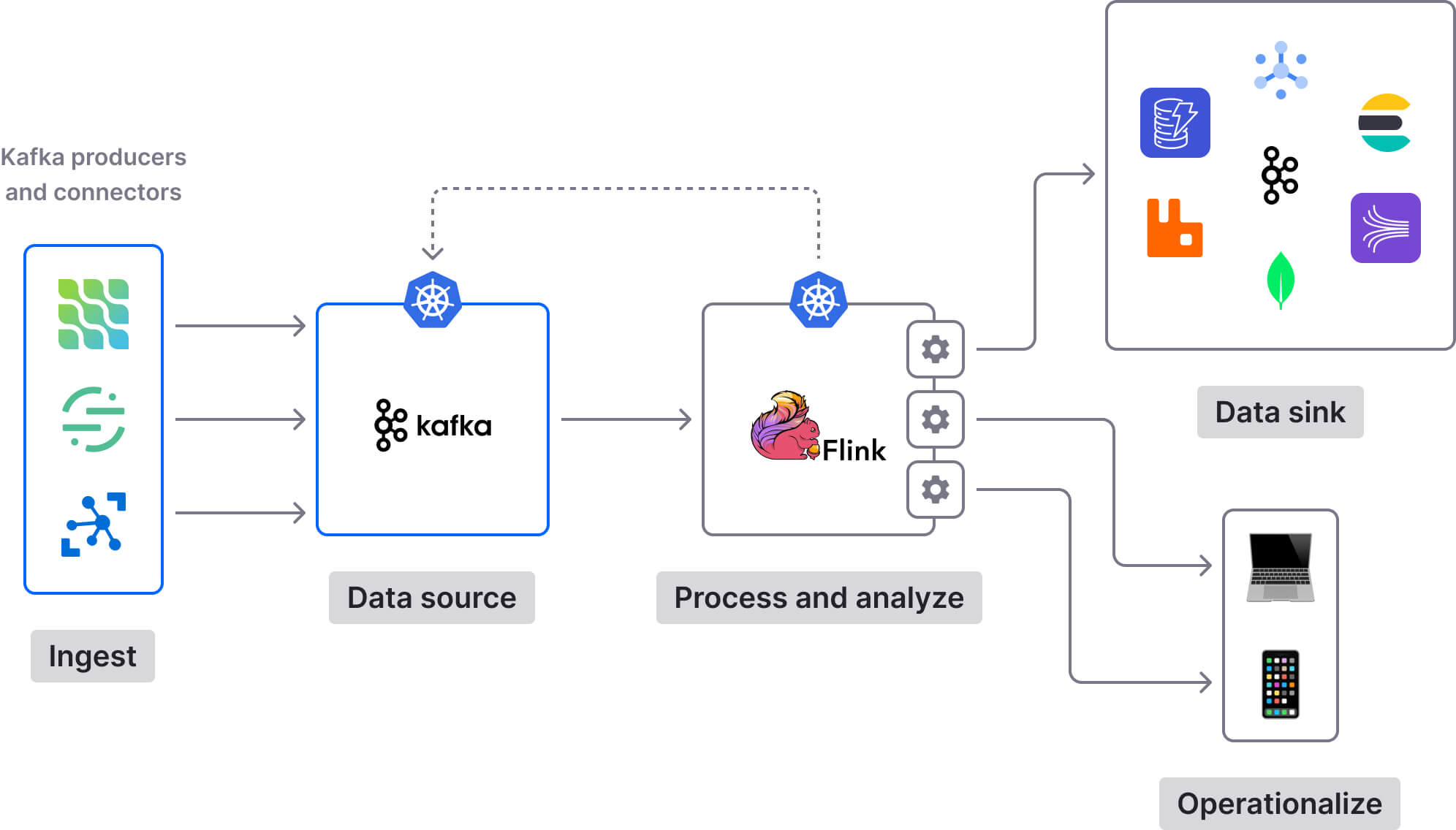
Not to mention that tools like PyFlink and PySpark are themselves complex and difficult to manage. For example, here are some of the challenges of working with PyFlink:
- It’s essentially a wrapper around Flink’s Java APIs. This means you might need Java expertise (in addition to Python) for debugging.
- It’s pretty code-intensive, with a complex, time-consuming workflow.
- It’s safe to expect a feature parity gap between Flink’s Java API and PyFlink. When new Flink features or improvements are launched, they are generally first available in the Java API and only later added to the Python API.
- It has a steep learning curve (up to a few months), including a DSL.
- Configuring and deploying PyFlink can be difficult, time-consuming, and expensive, often requiring a dedicated team. For instance, the Contentsquare engineering team worked for a year (!) to migrate from Spark to Flink and ensure everything worked as intended; it was a road riddled with challenges and gotchas they wished they had known earlier.
To learn more about PyFlink and its limitations (and strengths), give this deep dive a read.
On the other hand, if you’re using Quix Streams as your Python Kafka client, you don’t need a dedicated component for stateful stream processing. That’s because Quix Streams is a unified solution that serves as a Python client for Kafka as well as a stream processing library (with support for both stateless and stateful operations).
Furthermore, Quix Streams is much more straightforward to learn and operate than beasts like (Py)Flink. There’s no JVM, no cross-language debugging, no DSL. Additionally, if you deploy Quix Streams applications to Quix Cloud, you’re circumventing much of the infrastructure management overhead that comes with operating Flink in-house.
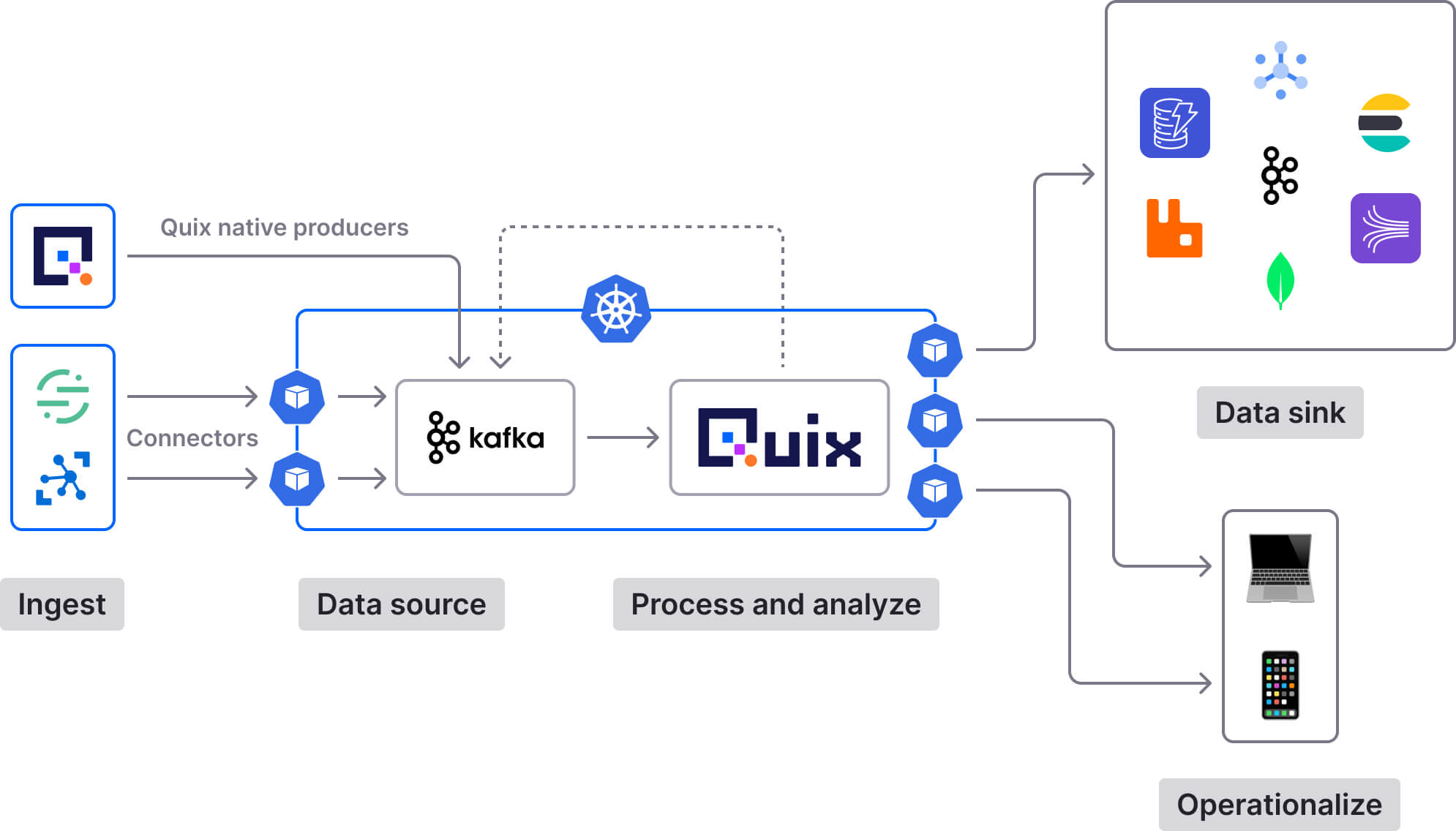
If you’re interested to learn more about the differences between Flink and Quix, check out this detailed comparison.
Which Python Kafka client should I use?
This very much depends on the specifics of your use case.
kafka-python offers a minimalistic approach that’s ideal for smaller projects. This client allows direct, low-level access to Kafka's core producer and consumer capabilities, making it suitable for those who need a straightforward solution that doesn’t impose any complex dependencies.
Confluent's Kafka Python client is engineered primarily for developers looking to take full advantage of Confluent’s extended capabilities. It integrates seamlessly with Confluent-specific elements like schema registry, Kafka Streams, and advanced security features. It’s a good choice for building enterprise-grade applications that require reliable, high-throughput messaging and basic transformations.
Quix Streams provides the most “Pythonic” experience of all three solutions. If you’ve previously used pandas, you’ll feel right at home with Quix Streams. This is due to its DataFrame-like API for consuming, transforming, and producing Kafka data. Similar to the Confluent client, Quix Streams is designed to handle high-velocity data streams resiliently and at scale. Additionally, if you have more complex requirements than simply publishing, consuming and applying basic transformations to Kafka messages, Quix Streams can help due to its stateful stream processing capabilities.
Get started with Quix Streams
If you want to benefit from a unified solution that serves both as a Python client for Kafka and as a Python stream processing library, I invite you to try Quix Streams.
Installing Quix Streams is as simple as:
python -m pip install quixstreams
Once that’s done, follow the Quickstart guide to learn how to create and run your first Quix Stream apps.
You might also want to check out the Quix templates gallery — a collection of pre-built projects and ready-to-run code snippets to kickstart your application development process using Quix Streams.
Last updated:
May 17, 2024

Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.




