Don’t dump data. Build better pipelines.
Data warehouses are where good decisions go to die. Reinvent your data pipelines with the power of stream processing — extracting value from data the moment it is created.
What can you build with Quix?
ETL and ELT
Extract, Transform and Load — this process dumps valuable data in a lake. Dump, pull, transform makes data difficult to manage, duplicative and unreliable. Modernize this process by handling data as it is created (in a stream), processing it in-memory, and keeping only clean, orderly data. Future users will thank you.
Change data capture
You need to know when data changes at the source so you can take action — whether to modify a database, automate new responses or change the way you process it. Using ELT to sync data stores doesn’t cut it. But with stream processing, you’ll immediately and reliably recognize data changes and be ready to act on new variables.
Smart caching
Much of the data stored in warehouses is hidden deep in the cloud — so logging into your bank for a transaction history will take time to query, retrieve and serve. Why not do it better? Recognize customers and use ML to predict what that customer is likely to query. Then selectively pre-load data to serve it immediately, reducing latency.
Stream analytics
Build better business intelligence dashboards using the streaming infrastructure. Aggregate data from any source, layer on business logic, then easily query to generate high-value reports. Now you can report on-demand or on any schedule, so reporting is always current in real time. This automation regardless of when or how often data arrives.
Machine learning
Empower your data scientists to self-serve streaming data. Let them explore, build, test, deploy and monitor their ML models without (much) support from you. Just create a sandboxed workspace, connect it to raw data streams, and off they go. You can also hook their real-time model results to production to connect them to your data consumers.

Changing data engineering for good
Quix was founded by Formula 1 engineers to bring the power of stream processing to data engineers in any industry.
Their expertise in unifying hundreds of data sources and millions of data points per second created a platform that helps data engineers manage a massive volume and velocity of data.
By processing data in-memory at the moment it is created, you can capture more value from your data while capably managing a high-volume pipeline.
It’s flexible, powerful, resilient and efficient. Ready to learn more? Chat with a friendly expert about what else you can do with Quix.
From the blog
Introducing Streaming DataFrames


Navigating stateful stream processing

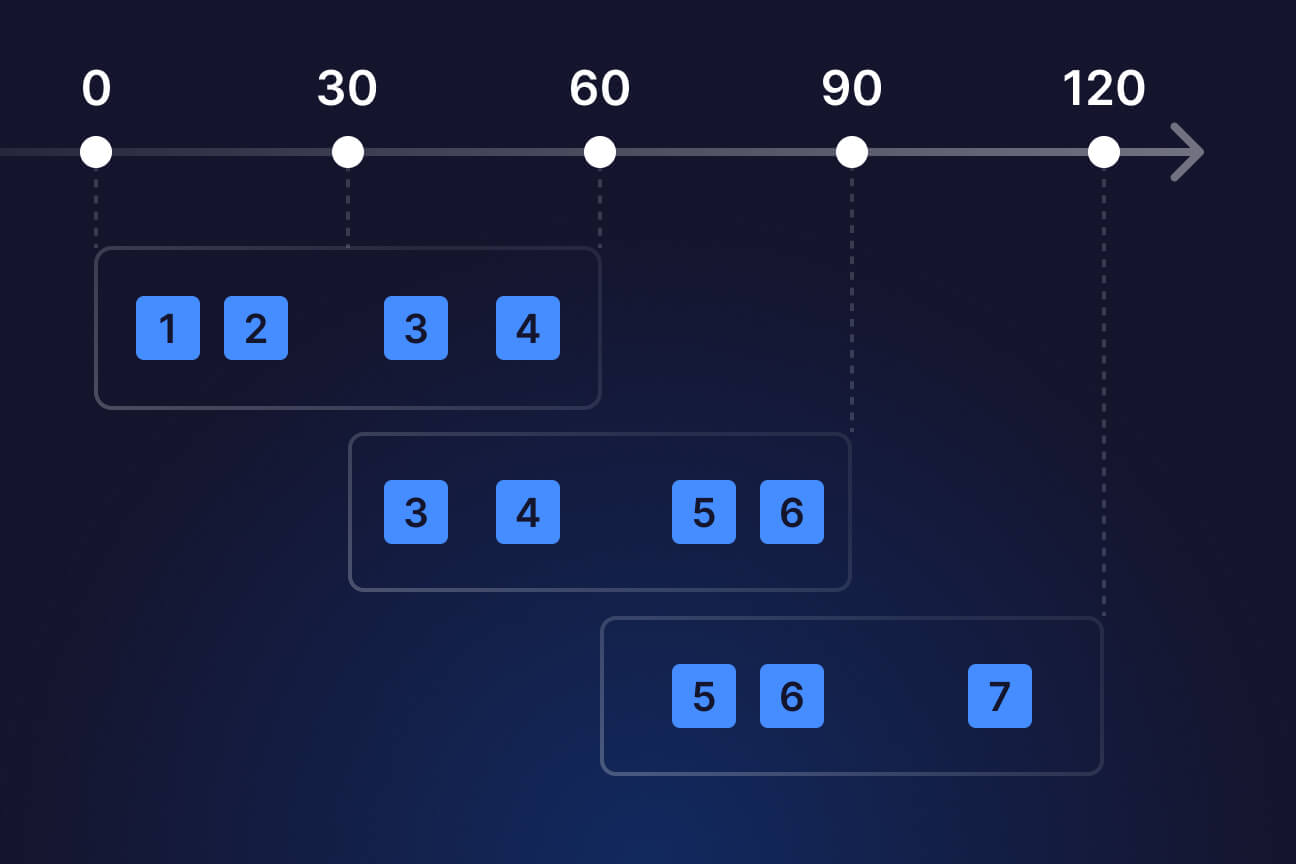
A guide to windowing in stream processing

Why the data pipeline is changing everything
Find out why analysts and market-watchers agree that traditional data processing must be replaced by stream processing. It’s happening now as innovators embrace new opportunities for greater personalization, automation and revenue.
Fill out the form to receive the white paper to your inbox.
